
Training
A Journey into Parallel Python - Episode 1
Episode 1: Introduction to Multiprocessing
Python is a versatile and powerful programming language known for its simplicity and ease of use. However, as programs grow in complexity, there is a pressing need for efficient execution, especially when dealing with computationally intensive tasks. This is where parallel computing comes into play. In this blog series, we will explore various aspects of parallel Python, starting with multiprocessing.
When to Use Parallelism
Parallel computing is particularly advantageous when dealing with tasks that can be split into smaller independent sub-tasks. These sub-tasks can be executed concurrently on multiple processors, reducing the overall execution time.
Introducing Multiprocessing Module
Python’s multiprocessing module provides a powerful way to harness the full potential of multi-core processors by creating multiple processes, each with its own Python interpreter. This enables true parallel execution and makes it an easy choice for tasks that benefit from parallelism.
The Experiment: Parallel Prime Number Search
In this experiment, we will tackle a classic problem: finding prime numbers. A straightforward, sequential approach to finding prime numbers can be slow and inefficient when dealing with a large range of numbers. Our goal is to compare the performance of a sequential approach with parallel solutions using multiprocessing.
Serial Solution
In our journey to explore the benefits of parallel computing in Python, we begin with a foundational experiment: finding prime numbers using a sequential approach. This experiment sets the baseline for performance against which we will compare the results of our parallel solutions.
We start by iterating through the range of numbers one by one. For each number, we apply a primality test using the is_prime function. This function checks whether a number is prime or not, and, after that, checks another number. While this method is straightforward and easy to understand, it can become sluggish when dealing with a large range of numbers.

Plain Multiprocessing
Plain multiprocessing involves distributing every number to a process, each running the prime-checking function concurrently. The results are then collected and combined to identify prime numbers.
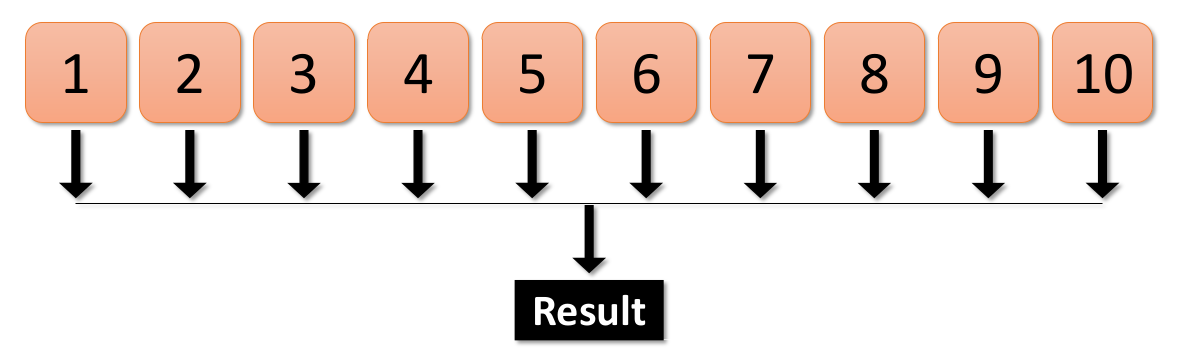
Multiprocessing with Chunks
In this alternative approach, we divide the range of numbers into smaller chunks and assign each chunk to a separate process. The chunk results are then collected and combined to identify prime numbers.
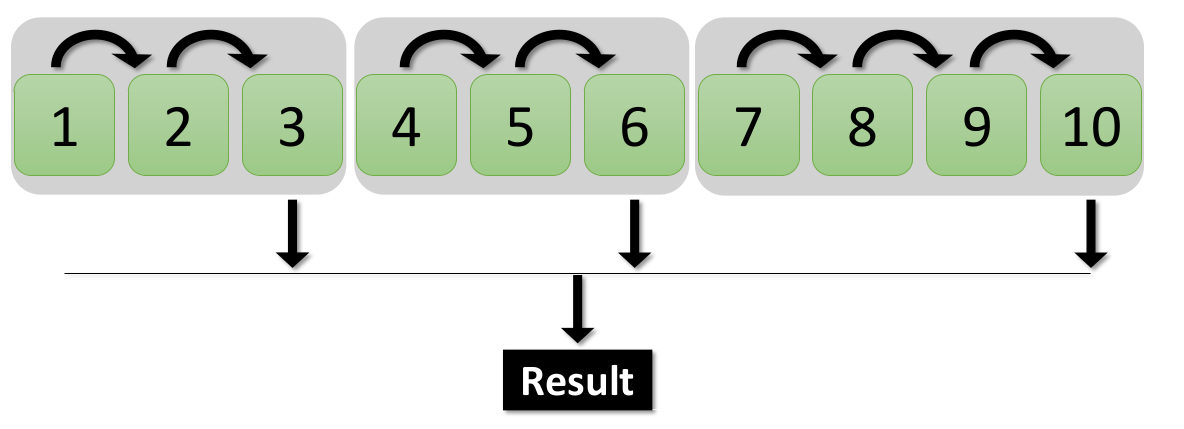
Serial vs. Parallel: A Performance Comparison
In our journey to explore the world of parallel Python, we conducted a series of experiments to compare the performance of different parallel solutions in the context of prime number generation. The experiments were conducted on three different ranges of numbers: 10^6, 10^7, and 10^8. We measured the execution time in seconds for each approach and configuration. The expereiments were done on ARC4 using an entire node with 40 cores and 192GB of memory.
Serial Approach
We initiated our exploration by implementing a sequential prime number search, which served as the baseline for our performance comparison. The results were as follows:
- For 10^6 numbers, the sequential approach took approximately 2.88 seconds.
- For 10^7 numbers, the execution time increased to more than a minute (71.11 seconds).
- With a larger range of 10^8 numbers, the execution time significantly escalated to approximately 32.36 minutes (1941.63 seconds).
These execution times demonstrated the inefficiency of a sequential approach when dealing with larger datasets. It also provided us with a baseline to measure improvements achieved by parallelism.
The non-linear scaling of execution time can be primarily attributed to the nature of the prime search algorithm. This algorithm involves a for loop that iterates with the size of the input number. As the input size increases, the number of iterations required by the algorithm grows proportionally. Consequently, the execution time exhibits a non-linear increase, making the algorithm less efficient for larger input sizes.
While hardware constraints play a role in overall execution time, the algorithm’s inherent complexity and its dependence on input size are the dominant factors in this context. Understanding the algorithm’s behaviour is the first step in identifying areas for improvement.
In the subsequent sections, we will explore how parallelism can address these challenges and significantly improve the performance of prime number generation in Python.
Parallel Plain Approach
We then explored a plain parallel approach, distributing the prime number search across multiple processes. The results showed promising improvements:
- For 10^6 numbers, the parallel plain approach took approximately 2.41 seconds, making it approximately 1.19 times faster than the serial version.
- With 10^7 numbers, the execution time reduced to approximately 18.56 seconds, achieving a speedup of about 3.82 times.
- For 10^8 numbers, we observed a substantial reduction in execution time, with approximately 4 minutes (238.96 seconds), making it approximately 8.14 times faster than the serial approach.
Although we have attempted to divide the workload into 40 cores theoretically, the improvement in simulation time is not significant. This may be due to the nature of the problem as checking whether a number is prime or not is not a time-consuming task. The lower performance improvement can be attributed to the substantial overhead introduced by parallelism, particularly the creation and management of multiple processes and communication between them. Often, the speed at which processes complete their tasks can surpass the efficiency of communication between cores. This leads to underutilization of available CPU cores. The image below depicts this finding: we never managed to have 40 cores using 100% of CPU for Python tasks.
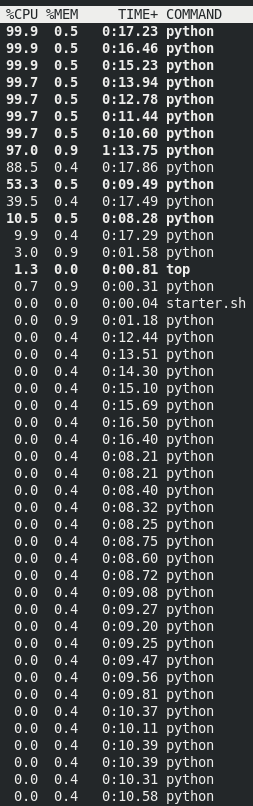
Parallel Chunk Approach
Next, we implemented a parallel chunk approach, where we divided the range of numbers into chunks and assigned each chunk to a separate process. This is an attempt to create larger process to avoid the communication overhead. The task here is find the right ballance between the time we lose managing all processes and keeping all cores using 100% of CPU as much as possible. This approach allowed us to fine-tune the level of parallelism. The results for 40 chunks were particularly impressive:
- For 10^6 numbers, the parallel chunk approach took approximately 0.27 seconds, showcasing a substantial improvement, approximately 10.67 times faster than the serial version.
- With 10^7 numbers, execution time reduced to approximately 4.09 seconds, achieving a remarkable speedup of about 17.38 times.
- Even with the most extensive range of 10^8 numbers, the execution time was significantly reduced to approximately 1.62 minutes (97.32 seconds), making it approximately 19.98 times faster than the serial approach.
By using chunks, every process spend more time running and less time communicating. This improves the overall efficiency of the experiment. As you can see bellow, with this approach we manage to hit all 40 cores:
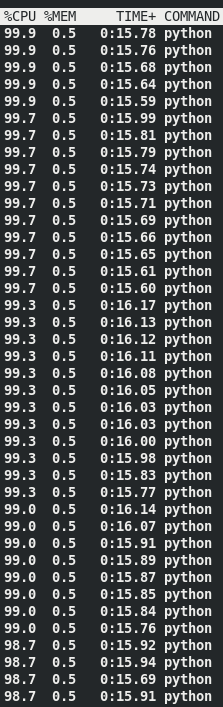
Chunk size optimization
The last thing to be analysed is the amount of chunks we use (sometimes called amount of workers). See the plot related with the larger problem:
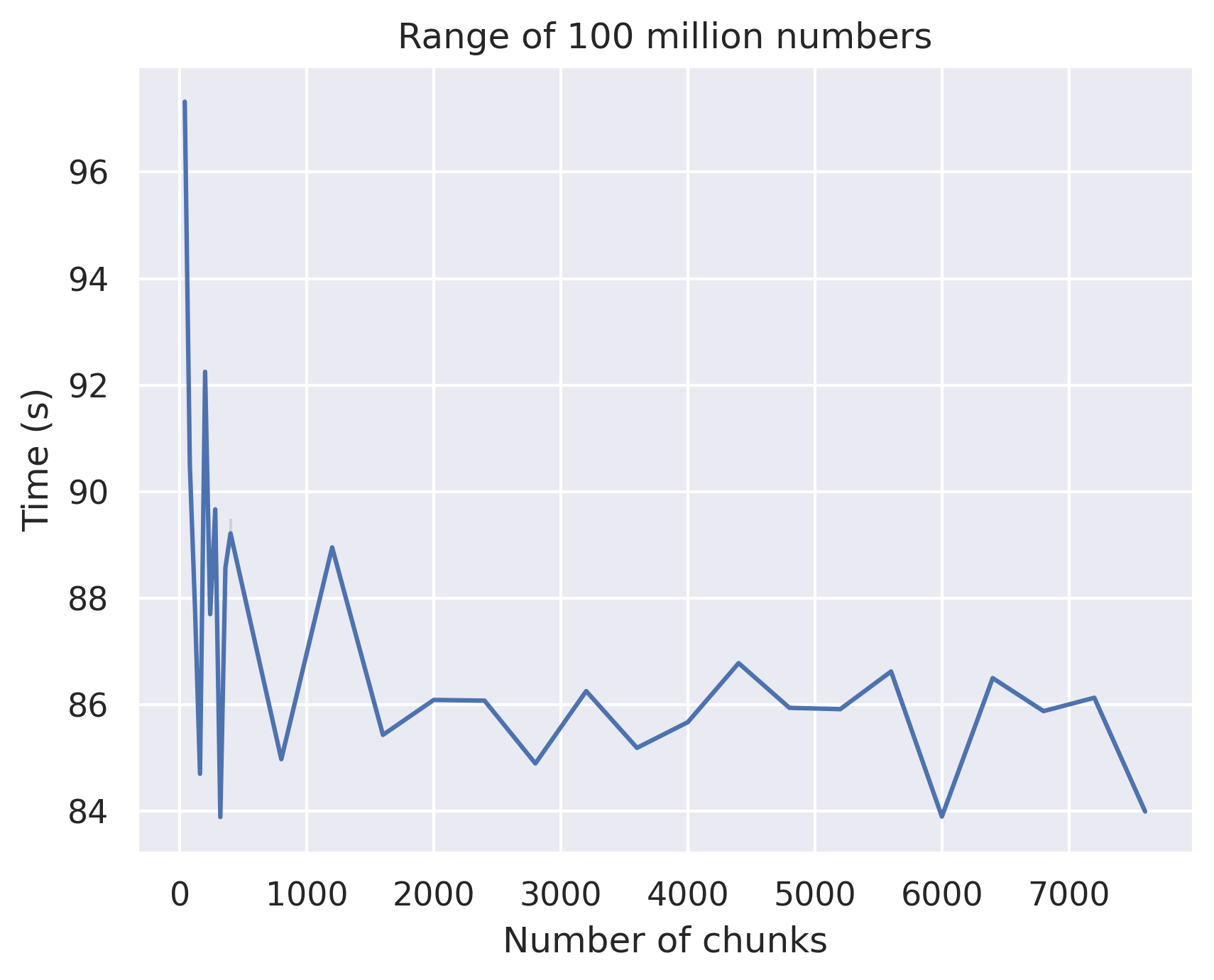
Optimizing the number of chunks in the parallel chunk approach is essential. You can notice in this example that employing 40 chunks may not yield the best performance. This observation is rooted in the fact that prime checking a small number is considerably quicker than prime checking a larger number, so check 0-1000 is quicker than check 1001-2000. As a result, some cores complete their tasks rapidly, while others are still operating at full capacity. Striking a balance is the key - having enough chunks ensures that when the quicker intervals finish, a new process can efficiently begin on the same core. However, it’s crucial not to have an excessive number of chunks, as this can lead to excessive overhead in communication, which could potentially offset the time gained through core optimization.
Discussion
The experiments clearly highlighted the advantages of parallelism in Python, particularly when dealing with computationally intensive tasks. The plain parallel approach, which distributed the workload one a one among processes, provided a noticeable speedup compared to the sequential approach.
The parallel chunk approach, where we fine-tuned the level of parallelism by dividing the workload into chunks, demonstrated the most significant performance gains. It showcased the potential for leveraging the full power of multi-core processors in Python.
These results underscore the critical role of configuring parallelization for unlocking its full potential. It’s important to recognize that every problem exhibits unique characteristics, and the optimal configuration may differ from what we’ve uncovered in the context of prime number searching. The primary aim of this blog post is to enhance your understanding of parallelization principles, equipping you with the knowledge and insights to adapt these concepts to your specific problem domains. By grasping how parallelization operates, we hope you’re better prepared to navigate the intricacies of parallel computing and apply this valuable expertise to your own diverse range of challenges.
In the subsequent posts of this series, we will delve deeper into parallel Python, exploring various parallel frameworks, advanced techniques, and best practices to further optimize your Python code for parallelism.
Please forward this blog to a friend!
Appendix
Results Table
| Type | Number of chunks | Time (s) for 10^6 numbers | Time (s) for 10^7 numbers | Time (s) for 10^8 numbers |
|---|---|---|---|---|
| Serial | - | 2.8817241191864014 | 71.11308193206787 | 1941.6339194774628 |
| Parallel plain | - | 2.4120452404022217 | 18.561339616775513 | 238.9633448123932 |
| Parallel chunk | 40 | 0.2703585624694824 | 4.094743490219116 | 97.31855487823486 |
| Parallel chunk | 80 | 0.24828743934631348 | 3.825242280960083 | 90.49211573600769 |
| Parallel chunk | 120 | 0.252028226852417 | 3.7143449783325195 | 87.85042238235474 |
| Parallel chunk | 160 | 0.2476975917816162 | 3.532663106918335 | 84.7046332359314 |
| Parallel chunk | 200 | 0.25487828254699707 | 3.8439860343933105 | 92.25035429000854 |
| Parallel chunk | 240 | 0.2679781913757324 | 3.7825417518615723 | 87.7009825706482 |
| Parallel chunk | 280 | 0.24977588653564453 | 3.7289867401123047 | 89.66810250282288 |
| Parallel chunk | 320 | 0.24884271621704102 | 3.53690242767334 | 83.89400172233582 |
| Parallel chunk | 360 | 0.25550150871276855 | 3.665968656539917 | 88.5750949382782 |
| Parallel chunk | 400 | 0.24846792221069336 | 3.839165449142456 | 88.95045518875122 |
| Parallel chunk | 400 | 0.25121283531188965 | 3.779390573501587 | 89.48629188537598 |
| Parallel chunk | 800 | 0.2497234344482422 | 3.5345916748046875 | 84.97951412200928 |
| Parallel chunk | 1200 | 0.2505936622619629 | 3.643186092376709 | 88.95472049713135 |
| Parallel chunk | 1600 | 0.25502467155456543 | 3.566555976867676 | 85.43585753440857 |
| Parallel chunk | 2000 | 0.25293874740600586 | 3.6725733280181885 | 86.09180688858032 |
| Parallel chunk | 2400 | 0.2573375701904297 | 3.570603847503662 | 86.07818627357483 |
| Parallel chunk | 2800 | 0.25385212898254395 | 3.64874529838562 | 84.89961862564087 |
| Parallel chunk | 3200 | 0.2503926753997803 | 3.6192290782928467 | 86.25797414779663 |
| Parallel chunk | 3600 | 0.25528526306152344 | 3.632573127746582 | 85.19222736358643 |
| Parallel chunk | 4000 | 0.264545202255249 | 3.541602849960327 | 85.67413830757141 |
| Parallel chunk | 4400 | 0.2594177722930908 | 3.6193411350250244 | 86.78273630142212 |
| Parallel chunk | 4800 | 0.25583815574645996 | 3.59921932220459 | 85.94321131706238 |
| Parallel chunk | 5200 | 0.255126953125 | 3.626305103302002 | 85.91821503639221 |
| Parallel chunk | 5600 | 0.2588353157043457 | 3.6022090911865234 | 86.6257905960083 |
| Parallel chunk | 6000 | 0.2574269771575928 | 3.5766496658325195 | 83.9020631313324 |
| Parallel chunk | 6400 | 0.268543004989624 | 3.629772901535034 | 86.50152969360352 |
| Parallel chunk | 6800 | 0.2680470943450928 | 3.6349997520446777 | 85.8815438747406 |
| Parallel chunk | 7200 | 0.26164889335632324 | 3.6494381427764893 | 86.1327075958252 |
| Parallel chunk | 7600 | 0.2591238021850586 | 3.566507577896118 | 83.9977662563324 |
Requirements
- python = 3.11.5
- numpy = 1.26.0
Imports
import numpy as np
import time
from multiprocessing import Pool, cpu_count
from itertools import chain
Primes code
def is_prime(n):
"""
Check if a number is prime.
Args:
n (int): The number to check for primality.
Returns:
bool: True if the number is prime, False otherwise.
"""
if n <= 1:
return False
if n <= 3:
return True
if n % 2 == 0 or n % 3 == 0:
return False
i = 5
while i * i <= n:
if n % i == 0 or n % (i + 2) == 0:
return False
i += 6
return True
def find_primes_in_range(numbers):
"""
Find prime numbers in a range of numbers.
Args:
numbers (numpy.ndarray): An array of numbers to check for primality.
Returns:
list: A list of array of Boolean values indicating whether each number is prime.
"""
primes = [is_prime(n) for n in numbers]
return primes
Experiments Code
def serial_test(numbers):
"""
Perform a serial test to find prime numbers in a range of numbers.
Args:
numbers (numpy.ndarray): An array of numbers to check for primality.
Returns:
numpy.ndarray: An array of prime numbers.
float: The time taken for the operation.
"""
t0 = time.time()
serial_primes = find_primes_in_range(numbers)
serial_primes = numbers[serial_primes]
serial_time = time.time() - t0
return serial_primes, serial_time
def parallel_plain_test(numbers, num_processes):
"""
Perform a parallel plain test to find prime numbers in a range of numbers using multiprocessing.
Args:
numbers (numpy.ndarray): An array of numbers to check for primality.
num_processes (int): The number of processes to use for parallelization.
Returns:
numpy.ndarray: An array of prime numbers.
float: The time taken for the operation.
"""
t0 = time.time()
with Pool(processes=num_processes) as pool:
parallel_primes = pool.map(is_prime, numbers)
parallel_primes = numbers[parallel_primes]
parallel_time = time.time() - t0
return parallel_primes, parallel_time
def parallel_chunk_test(numbers_chunk, num_processes):
"""
Perform a parallel chunk test to find prime numbers in a range of numbers using multiprocessing.
Args:
numbers_chunk (list): A list of chunks, each containing numbers to check for primality.
num_processes (int): The number of processes to use for parallelization.
Returns:
numpy.ndarray: An array of prime numbers.
float: The time taken for the operation.
"""
t0 = time.time()
with Pool(processes=num_processes) as pool:
chunk_primes = pool.map(find_primes_in_range, numbers_chunk)
flat_primes = list(chain.from_iterable(chunk_primes)) # 1D list
chunk_primes = numbers[flat_primes]
chunk_time = time.time() - t0
return chunk_primes, chunk_time
if __name__ == '__main__':
num_processes = cpu_count()
total_numbers = 1_000_000 # up to 1_000_000_00
numbers = np.arange(total_numbers)
print(num_processes, total_numbers)
# Serial version
serial_primes, serial_time = serial_test(numbers)
print(f"Serial version found {len(serial_primes)} primes in {serial_time} seconds.")
# Plain Multiprocessing - All cores
plain_primes, plain_time = parallel_plain_test(numbers, num_processes)
print(f"Parallel plain version found {len(plain_primes)} primes in {plain_time} seconds.")
# Multiprocessing with chunks
chunk_scale = list(range(10, 200, 10))
for n in chunk_scale:
numbers_chunk = np.array_split(numbers, num_processes * n)
chunk_primes, chunk_time = parallel_chunk_test(numbers_chunk, num_processes)
print(f"Parallel chunk version using {n * num_processes} processes in {chunk_time} seconds.")
HPC Job Submission
#Run with current environment (-V) and in the current directory (-cwd)
#$ -V -cwd
#Request some time- min 15 mins - max 48 hours
#$ -l h_rt=05:00:00
# Ask for a full node (40 cores and 192G)
#$ -l nodes=1
#Get email at start and end of the job
#$ -m be
#Now run the job
python primes.py